Andy Jassy delivered a ripping AWS re:Invent 2019 keynote. The key theme was around transformation. Of course, there were heaps of exciting announcements. Strap in for our wrap up! As there’s a lot to cover, it’s split into two parts with this being the first.
Transformation
So, following the theme, if you are going to transform your business with the Cloud, what are the key considerations that you need to think about? Andy framed the keynote around these 6 goals.
- Start with building the business momentum and make the decision to move;
- Don’t stop, move quickly & keep the momentum;
- What are you going to move? What are you going to keep?
- Decide how to deal with your data needs. There are different solutions for a variety of use cases;
- Use the right tools to gain the insights. Machine Leaning in the Cloud is the new normal;
- Break through the barriers with innovative solutions.
Let’s delve into how AWS is enabling the modern transformation through the new announcements from the re:Invent 2019 keynote.
Compute

Despite the rise of serverless and containers, compute remains a major focus for AWS and their customers. In 2019 there are 4 more EC2 instance types than 2 years ago! The key announcements included:
- New EC2 instances for HPC and Machine Learning workloads, all based on the groundbreaking Nitro platform;
- New EC2 instances built around the custom chipset Inferencia. This chipset is optimised for Machine Learning workloads;
- Fargate is now available for EKS. Fargate is a serverless technology for containers. With Fargate, you don’t have to manage the underlying compute instances in your container cluster. It has been available in ECS for a while and today it can be used with EKS;
- Finally, the AWS Compute Optimizer is a machine learning service that uses metrics from your AWS compute environment to recommend optimisations in instance sizes.
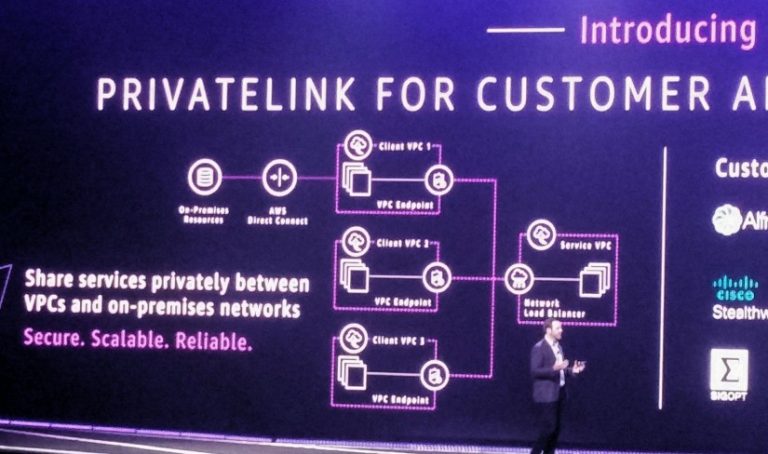
Network
No matter how good your service is, your customer need to be able to connect to it. Network is the passata di pomodoro of the Cloud world. Get it wrong and everyone knows about it. Get it right and nobody notices.
re:Invent 2018 introduced Transit Gateway. It has quickly become an essential tool for AWS environments. Today, AWS released a number of new features for it.
- Support for multicast. Multicast delivers a single stream of data to many end points in parallel. It is a preferred protocol for streaming multimedia content to a group of subscribers;
- Support for multi-region connectivity. Until now, VPCs connected via Transit Gateway had to be in the same region. That restriction has now been lifted with the support for inter-region peering. Like all services, traffic between regions is encrypted on the AWS backbone;
- Accelerated site to site VPN. Traffic from your customer gateway device is routed through the nearest AWS edge location. From there, it traverses the AWS global network to reach the VPN endpoint in AWS in the most efficient way possible;
- Network Manager provides a single point to manage and monitor your AWS global network. It includes all attachments associated with the Transit Gateway. In addition, launch partners, including Cisco and Aruba, integrate with the AWS API to register on-premises devices and automatically create VPN connections!
In addition to the Transit Gateway updates, you can now associate a route table with an Internet Gateway. This means that you can direct all ingress traffic to an appliance for scanning or for an IPS/IDS service far easier than before.
Data analytics

Data is everywhere and it’s not all the same. Different use cases require different solutions. Which is why AWS has a rich set of capabilities which today have only grown.
There has been a heap of new features in Redshift.
- We are particularly excited about Federated Query. It allows you to query and analyze data across operational databases in RDS, data warehouses in Redshift, and data lakes in S3 without having to move the data;
- In recent years, storage throughput has increased by 12x while the CPUs ability to process data in memory has only increased by 2x. Traditional, if you wanted more CPU throughput, you also had to increase the on-instance storage, even if you didn’t need it. The new Redshift instance RA3 can scale CPU and storage independently, providing more bang for your buck;
- AQUA accelerates queries by moving compute closer to the storage layer. This eliminates the need to move data from the storage layer to the compute clusters, accelerating query performance;
As S3 becomes more and more popular as a data lake, access control from disparate source becomes a challenge. Enter Amazon S3 Access Points. It will simplify access from applications, avoiding unintended access.
Finally, we have UltraWarm, a strange name for an important announcement. It’s a low-cost, warm storage layer for Amazon Elastisearch, backed by S3. Significantly, storage savings are in the region of 90% vs hot storage. This allows you to query a far larger pool of data than previously at a much lower cost. A classic use case is for operation data to identify and remediate issues.
Managed Cassandra
Do you depend on a Cassandra cluster for your workloads? If so, you might want to look at the new Amazon Managed Apache Cassandra Service. It’s a fully managed serverless implementation that is highly available out of the box. Designed with security in mind, it only accepts TLS based connections and allows you to concentrate on your data and not the cluster management.
Code analysis
How do you know if your code is efficient? Do you perform regular code reviews? Do you follow secure coding standards?
If you do (and you should), you should pay attention to Amazon CodeGuru. It’s a new service that uses machine learning to automatically analyse your code. Amazon use it internally and have now exposed it as a service. It will provide recommendations to optimise your code. Today, it only support Java but that will change with more language and standards supported.
More from the AWS re:Invent 2019 keynote…
Stay tuned for part 2 of our announcement round up!